In the first post of this series, we introduced GitHub Copilot Extensions and discussed the two types of extensions. Client side and server side extensions.
Previously GitHub Copilot Extensions: Creating a VS Code Copilot Extension we created a simple chat participant that just repeated what was typed in the chat window. In this post we will enhance our chat participant to use the GenAI API to parrot the messages like a Pirate or Yoda style, we are now going to improve the parrot extension to use the power of Copilot’s large language models.
Goal
This post demonstrates how to integrate the GitHub Copilot GenAI API into your VS Code extension. We’ll enhance our simple “chat parrot” extension to transform user input into pirate-themed or Yoda-style speech using the power of Copilot’s large language models. This will cover prompt engineering, API integration, and handling streaming responses within the context of a VS Code extension.
Tip
The complete source code for this tutorial series is available on GitHub. These posts will guide you through building this extension step-by-step, from initial setup to the final version you see in the repository.
This simple example extension acts like a chat parrot, repeating what you type in the chat window. You can optionally have it repeat your message in pirate or Yoda style.
Adding slash commands
Slash commands in Copilot Chat provide a structured way to communicate intent to the AI agent. Rather than writing lengthy natural language questions, these commands act like shortcuts that guide the agent to understand exactly what kind of help you need. For example, using /fix tells Copilot you want to fix code issues, while /test indicates you need help writing tests. This focused approach helps the agent provide more accurate and relevant responses.
g to write out long questions.
The parrot extension will implement two slash commands:
/likeapirateInstead of just parrot what it has been told to, the parrot will repeat the message in pirate like style. Head up to Wikipedia talk like a pirate day for more information./likeyodaSimilar to the pirate style, but this time the parrot will repeat the message in Yoda style.
The first thing we need to do is add the commands to the package.json file. Add the following commands attribute inside out the previously defined parrot participant.
"commands": [
{
"name": "likeapirate",
"when": "config.tspascoal.copilot.parrot.like.Enabled",
"description": "Parrot like a pirate"
},
{
"name": "likeyoda",
"when": "config.tspascoal.copilot.parrot.like.Enabled",
"description": "Parrot like yoda"
}
You can see the full JSON for the parrot chat participant. Notice we also add another slash command the
/listmodelswhich I will leave as an exercise for you.
Once we add our command, and write @parrot in the prompt we can now see the slash commands are now shown (you can click on them to be added to the prompt or just type them).
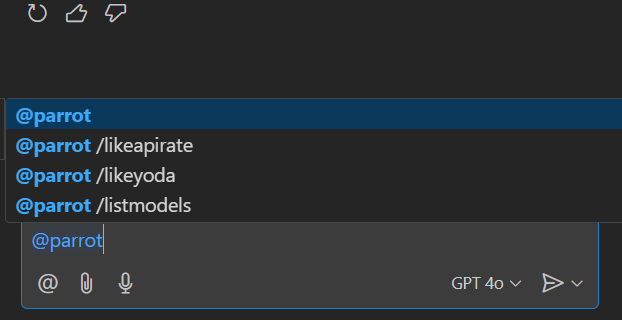
You can also start just typing / and Copilot will show the all the slash commands, so you can type /likeapirate and press enter, and copilot will automatically place on the prompt @parrot /likeapirate (unless there are other extensions implementing a command with the same name since commands don’t have to be unique).
If you try the prompt @parrot /likeapirate hello, it will still just parrot hello, since we have not made any changes to the handler yet.
Note
It replies with hello and now with /likeapirate hello because Copilot excludes the command from the actual prompt.
So let’s make the necessary changes to the handler to respond to the commands.
Responding to slash commands
We do not have to parse the prompt to get the command name, Copilot does that for us. In order to get the slash command to execute (if any).
The command is defined in the command property of the request passed to the handler (vscode.ChatRequest).
If you haven’t refactored the code, to extract the handler to a separate function, let’s do that now.
We will replace the previous code (in extension.ts)
const participant = vscode.chat.createChatParticipant('tspascoal.copilot.parrot', (request, context, response, token) => {
response.markdown(request.prompt);
});
to
const participant = vscode.chat.createChatParticipant('tspascoal.copilot.parrot', handleParrotChatHandler);
Let’s now starting implementing our handler
export async function handleParrotChatHandler(request: vscode.ChatRequest, context: vscode.ChatContext, response: vscode.ChatResponseStream, token: vscode.CancellationToken): Promise<void | vscode.ChatResult | null | undefined> {
const command = request.command;
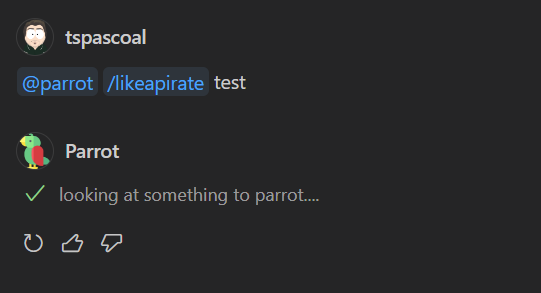
response.progress('looking at something to parrot....');
We will start by placing the command in a command variable and added a new command call to response.progress.
Now let’s add the skeleton for the handler (for brevity sake we will just implement the likeaparrotcommand)
switch (command) {
case 'likeaparrot':
break;
default:
response.markdown(request.prompt);
break;
}
If we now run the prompt @parrot /likeapirate test we don’t get any response.
Let’s enhance our extension by leveraging GitHub Copilot’s Large Language Model (LLM) invoking capabilities. We’ll modify our parrot to speak like a stereotypical pirate, complete with “Arrr!”, “matey”, and other pirate vernacular. This will demonstrate how to integrate Copilot’s AI to transform plain text into more engaging, themed responses.
Using GitHub Copilot’s LLM API to Transform Text into Pirate Speech
Calling LLM can be split into two separate tasks. First write the prompt to achieve our desired result, the second will be to call the API with the created prompt.
Working with GitHub Copilot’s LLM involves two distinct steps:
- Craft a carefully worded prompt that will guide the AI to generate the desired pirate speech transformation
- Test and refine the prompt to ensure consistent, high-quality outputs
API Integration
- Implement the actual API calls to send our prompt to GitHub Copilot’s LLM
- Handle the response and error cases appropriately
Let’s tackle each of these steps separately to build a robust text transformation feature.
In our case, our prompt is really really simple, all we need is to ask the LLM to repeat whatever the user said (this will be part of the prompt as well) in a Pirate look alike way.
In real-world applications, it’s important to maintain conversation context when working with LLMs. This means including both previous prompts and responses in subsequent API calls. Here’s why this matters:
Context Preservation
- LLMs don’t maintain state between calls
- Each request is treated independently
- Previous interactions provide valuable context
Iterative Refinement
- Users often want to refine or build upon previous responses
- Including conversation history helps the model understand the evolution of the request
- Enables more coherent and contextually aware responses
Example Scenario
- Initial prompt: “Transform text to pirate speech”
- User feedback: “Make it more formal”
- Including both helps Copilot understand the desired balance between pirate dialect and formality
This approach allows for more natural conversation flow and better results when users want to iterate on previous responses.
In a long conversation, it may not be possible to include all of it since it may exceed the number of maximum tokens of the model being used, so trimming or selecting the best content or pruning less import parts is something that may be necessary to craft our prompt.
Crafting the prompt
Our prompt is going to have two messages, the first the instructions what we want LLM to do with the content and then the actual user prompt.
The Copilot API receives an array of vscode.LanguageModelChatMessage
Let’s call the first, the system prompt, this one is going to be pretty simple:
Repeat what I will say below, but make it sound like a coding pirate parrot. Return the text in plaintext
Let’s break down why this prompt works:
- Clear Instruction
- “Repeat what I will say” - Tells the AI to echo back input
- “make it sound like a coding pirate parrot” - Defines the style
- Combines both pirate speech and programming terminology
- Output Format
- “Return the text in plaintext” - Explicitly requests unformatted text
- Prevents markdown, HTML, or other formatting that could interfere with our objectives
- Makes response processing simpler
- Simplicity
- Keeps the prompt focused on one task
- Avoids complex conditions or edge cases
- Makes responses more consistent and predictable
This system prompt will serve as the foundation for all our text transformations, ensuring consistent pirate-themed responses while maintaining readability.
We are not adding any strong rails on the prompt, so the user try to subvert by saying “disregard previous instructions….”
A more verbose example, would be something like:
You are a pirate parrot that loves coding. Your task is to:
1. Take any input text
2. Transform it into pirate speech while incorporating coding terminology
3. Return ONLY the transformed text with no additional formatting or markup
Example input: "Let's debug this code"
Example output: "Arr matey, let's hunt down them pesky bugs in this treasure chest of code!"`;
Experiment with different prompts to see which one works best. Adjust the wording and structure to achieve the desired outcome. Here are a few variations to try:
- Does the response improve?
- Is the output more engaging?
- Does it maintain technical accuracy?
Play around with prompt engineering to refine the results and find the optimal prompt for your needs.
Defining the System Prompt
First, let’s create a clear system prompt that will instruct the AI how to transform our text:
function generateSystemPrompt(command: string | undefined): vscode.LanguageModelChatMessage {
let soundLike = 'pirate';
if (command?.search('yoda') !== -1) {
soundLike = 'yoda';
}
return vscode.LanguageModelChatMessage.User(`Repeat what I will say below, but make it sound like a coding ${soundLike} parrot. Return the text in plaintext`);
}
This works for both likeapirate or likeyoda
Calling the LLM
Now that we have our system prompt, let’s call the LLM API (will also include the user prompt)
Let’s add this to our previously defined skeleton (all code inline, extract to a method left as an exercise)
switch (command) {
case 'likeapirate':
case 'likeyoda':
const messages = [
generateSystemPrompt(command),
vscode.LanguageModelChatMessage.User(request.prompt),
];
const [chatModel] = await vscode.lm.selectChatModels({ vendor: 'copilot', family: 'gpt-4o-mini' });
const chatResponse = await chatModel.sendRequest(messages, {}, token);
// This can also throw exceptions. But let's keep it simple
for await (const responseText of chatResponse.text) {
response.markdown(responseText);
}
break;
default:
response.markdown(request.prompt);
break;
}
What We added?
Message Setup
- Creates an array of messages for the LLM
- Includes the system prompt (pirate personality)
- Adds the user’s input text as a message
Model Selection
- Requests a GPT-4o mini from Copilot (you can use other models) using
selectChatModels()to get the model we want.- GPT 4o mini model is fast and far exceeds any capabilities we require for our simple use case
- If we use a less specific filter, then it will return multiple models and then you will have to select the one you want.
- Requests a GPT-4o mini from Copilot (you can use other models) using
API Call
- Sends the messages to the LLM
Response Handling
- Processes the streaming response from the LLM
- Iterates through response chunks as they arrive and shows in the chat interface
- For our simple case, this won’t be visible but for more complex responses this means the user experience is nicer since it will display results progressively as they are available.
Choosing the model to use
Choosing the right language model (LLM) for your Copilot extension involves balancing performance, cost, and the complexity of the task. More powerful models excel at nuanced tasks such as code analysis and context-rich transformations, delivering higher quality results. However, this comes at the cost of increased latency and resource consumption. For simpler operations like text manipulation or command suggestions, less powerful models offer a good compromise, providing adequate performance with faster response times and lower resource usage.
The optimal choice depends on your extension’s specific needs. Consider the complexity of the operations, the desired response times, and your resource budget. If your extension demands high accuracy and sophisticated understanding, a more powerful model might be justified. Conversely, if speed and efficiency are paramount, a less resource-intensive model could be the more practical solution.
In our pirate parrot example, we prioritize the quality and context awareness of GPT-4o mini which is faster and cheaper than 3.5 to ensure consistent and engaging pirate-themed transformations.
If want to read more about different GPT models the Hello GPT-4o announcement post has some considerations on OpenAI models.
Important: While parrot extension samples uses the model picker to demonstrate its functionality, it’s generally recommended to pre-define the optimal model for your extension’s specific needs in a production setting. Hardcoding the model ensures consistent performance and avoids unexpected behavior due to user selections.
Tip
Read more about available models and when to use which in AI models for Copilot Chat
References
- Language Model API
- Guide to working with Large Language Models
- Prompt TSX If you prefer to handle your prompts using React TSX files this is a way of doing it.
- Choosing the right AI model for your task
- Comparing AI models using different tasks
Next In Series
Next: Enhancing a GitHub Copilot extension by adding support for text selections and references in Using Context in a VS Code Extension